dev/3: liftoff

It’s been a while (around 4 months!), so I figured I should give an update on some of the progress that I’ve made very recently in the project after working on some other smaller projects12. That being said, I haven’t forgotten about YADB and really hope to continue making progress on this project to explore more about databases.
If you only care about the feature improvements that I made to the database just skip to the next section
Last time I was working on the project I ran into a slight burnout I suspect this was due to working extremely hard (and maybe not in the smartest way) on the B+ tree implemenation (note to self: B+ trees are pretty tricky to implement right). As such I’ve slightly shifted my focus and methodology for this project. In particular I’m trying to make use of these two changes in future development:
- Focus on getting a very strong foundation and understanding of the database system component that I am building.
- Aim to make small achievable goals to promote a positive feedback loop for development.
For the first point, I’m now trying to make a point of getting a very solid understanding of the theory and other implemenations for many of the features of the database. In particular, I recently got a copy of “Database Management Systems” by Ramakrishnan and Gehrke which I’m using to give myself a brief explanation on the different components of database systems (this was very useful for the query optimization, executor, and catalog designs). Outside of the new book I’m still using the recorded lectures from the CMU intro to database class for topics of interest (not going through all of them, just the ones that I need as I require them). Lastly, I’ve been checking out how other databases handle some of these architecture choices, in particular postgres as the code is (in general) fairly easy to read with lots of VERY high quality documentation, plus it’s also another OLTP database so there should be some familiarity with my codebase.
To my second point, a while back I saw an interesting post on hackernews of a blog post written by Mitchell Hashimoto (creator of Vagrant, Terraform, and other tools). I found the post very enlightening in particular the focus on making small, achievable goals to keep yourself motivated while working on a big project. I think a big part of what was stalling previous development of YADB was just being kind of getting overwhelmed by the B+ tree implementation and all of the edge cases and handling concurrency, etc… This sort of lead to burnout so when I began again (maybe in the last month or so) my main goal was just to get something working. So, I did a bit of refactoring and made the storage engine interface generic so that I could temporarily create in-memory storage for storing tables. This made it easier to then focus on the higher levels in the stack including the optimizer, executor, and also the shell interface, and now to a (very very very simple) SQL shell!!!!!!!!!!!!!!!!!!!
New Features!!!!
Now for the new features in YADB! First off this update follows after one of the biggest milestones yet for YADB: we can now write queries in our own shell and execute (very very very limited) SQL queries.
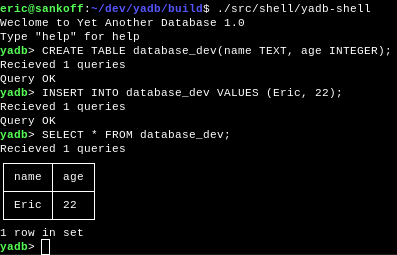
To do this some new system classes were created in particular:
- the shell
- parser and lexer (written in yacc and flex respectively)
- the optimizer
- the catalog
As mentioned earlier the mindset behind this project has shifted to focus on making incremental improvements that are easily visible, as such the implementations of these features, specifically the optimizer and SQL dialect are very simplified but I plan to make incremental improvements over time.
The optimizer in specific uses the most trivial implementations for each of the relational algebra operators and makes use of NO indicies, therefore the optimizer is in fact not doing much optimizing at all since currently there is only one way to execute queries.
In the future as I develop the optimizer it may be something I will make further posts on. In fact, once I’m done a disk based storage engine and index support I believe query optimization will be my main area of exploration.
Plans For The Future
As mentioned earlier, the current focus of the developer of YADB is to get basic DBMS features supported (on-disk storage, indexes, WHERE clauses), however once these are implemented at a relatively basic level I think the focus will be with experimenting with different query optimization techniques. In specific, I might take a crack at query compilation, taking inspiriation from Postgres’ JIT compiler for WHERE clauses, and maybe if that goes well even compiled execution plans (as seen in the hyper database), I mainly do this just to experiment as I don’t think there’s that much of an interest for me with just implementing yet another DBMS, ideally my vision for YADB is that I try some experimental techniques in the field on a relatively basic foundation, but we’ll see how that goes.